Um Data Lake é um repositório centralizado que permite armazenar todos os tipos de dados - estruturados, semi-estruturados e não estruturados - em escala massiva e em seu formato nativo. Diferentemente dos sistemas tradicionais, um Data Lake implementa uma abordagem "schema-on-read", onde a estrutura dos dados é definida apenas no momento da leitura, não na ingestão.hevodata+4
Flexibilidade de Dados: Capacidade de armazenar qualquer tipo de dado sem transformação prévia - desde logs de aplicações até imagens, vídeos e dados de sensores IoT.hevodata+1
Escalabilidade Horizontal: Crescimento automático conforme a demanda, suportando desde gigabytes até petabytes de informação.acceldata+1
Processamento Diversificado: Suporte a analytics em batch, streaming em tempo real, machine learning e business intelligence em uma única plataforma.snowflake+1
Custo-Efetividade: Armazenamento de baixo custo utilizando tecnologias como cloud object storage (Amazon S3, Azure Data Lake).chaossearch+1
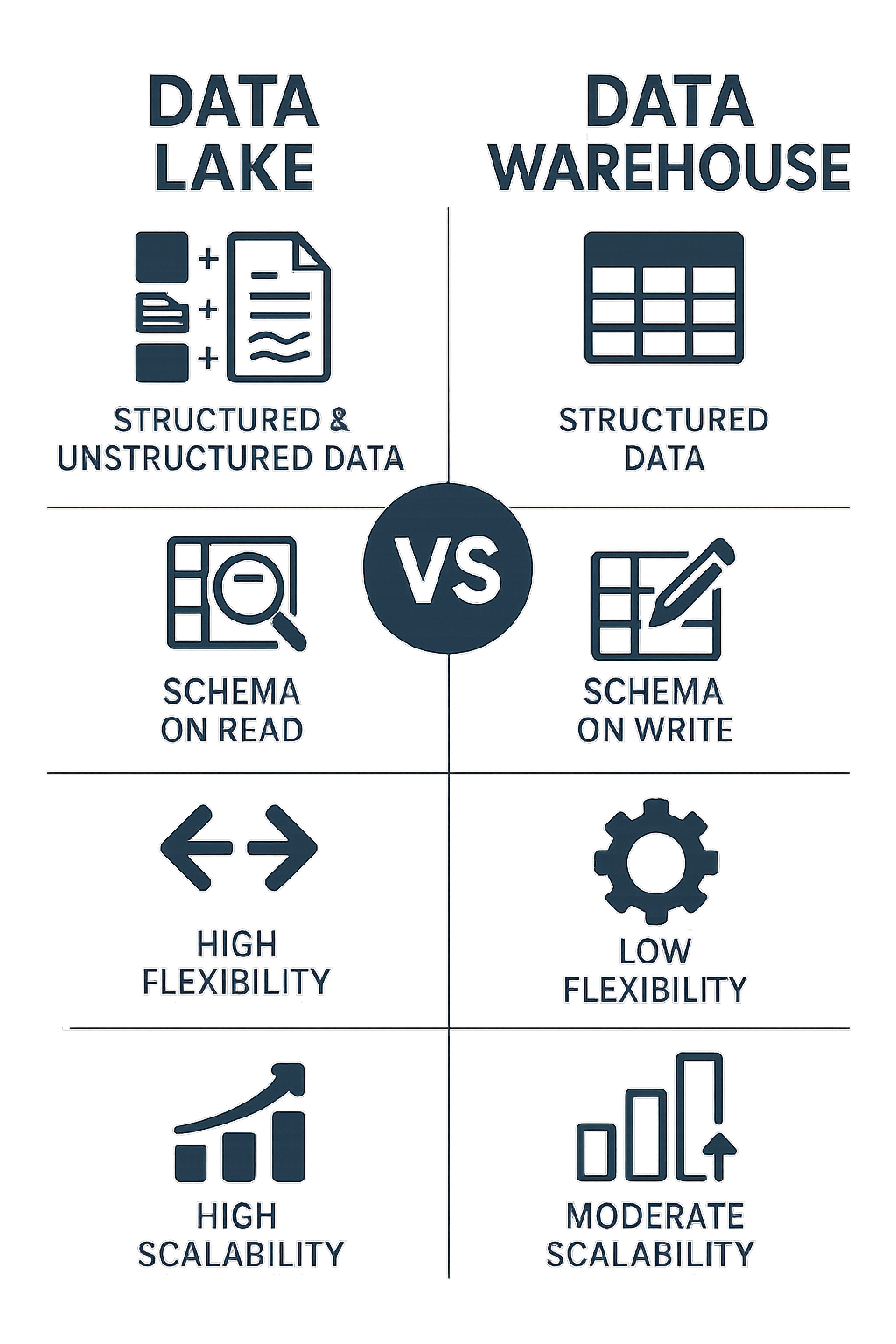
Comparação visual entre Data Lake e Data Warehouse
| Aspecto | Data Lake | Data Warehouse |
|---|---|---|
| Estrutura de Dados | Estruturados, semi-estruturados, não estruturados | Principalmente dados estruturados |
| Schema | Schema-on-read (flexível) | Schema-on-write (rígido) |
| Processamento | ELT (Extract, Load, Transform) | ETL (Extract, Transform, Load) |
| Custo | Baixo custo de armazenamento | Alto custo para grandes volumes |
| Agilidade | Alta agilidade para novos casos de uso | Menor agilidade, requer planejamento |
| Casos de Uso | Analytics exploratório, ML, IoT | BI tradicional, relatórios estruturados |



