https://docs.google.com/presentation/d/e/2PACX-1vS-cDguX0C4abP1hFZ7WNngujt2-Q4pgJ9O0qbPP1iEqZABNH_AmICeCyA1ggLv7g/pubembed?start=false&loop=false&delayms=3000
Introdução
Este módulo apresenta três algoritmos fundamentais de machine learning:
- K-Nearest Neighbors (KNN), método de classificação baseado em proximidade.
- K-Means, técnica de agrupamento (clustering) não supervisionado.
- Regressão Linear, modelo preditivo para dados contínuos.
Cada algoritmo será detalhado em termos de conceito, funcionamento, implementação e exemplos práticos, apoiados por diagramas ilustrativos.
1. K-Nearest Neighbors (KNN)
KNN é um algoritmo de classificação que atribui a classe de um ponto de consulta com base nas classes dos seus k vizinhos mais próximos no espaço de características.
- Conceito
- Espaço de características: cada instância é um vetor em ℝⁿ.
- Distância: geralmente euclidiana, mas podem usar Manhattan, Minkowski etc.
- Parâmetro k: número de vizinhos considerados.
- Funcionamento
- Calcular distâncias entre o ponto de consulta e todos os pontos de treino.
- Ordenar por distância crescente e selecionar os k primeiros.
- Votar na classe majoritária entre esses vizinhos.
- Escolha de k
- k muito pequeno: sensível a ruído (overfitting).
- k muito grande: suaviza fronteiras e pode causar underfitting.
- Seleção via validação cruzada.
- Complexidade
- Treino: O(1) (estratégia lazy).
- Inferência: O(n·d) por consulta (n = número de pontos de treino, d = dimensões).
- Aplicações
- Detecção de anomalias.
- Sistemas de recomendação simples.
- Classificação de texto ou imagem em tarefas de protótipo.
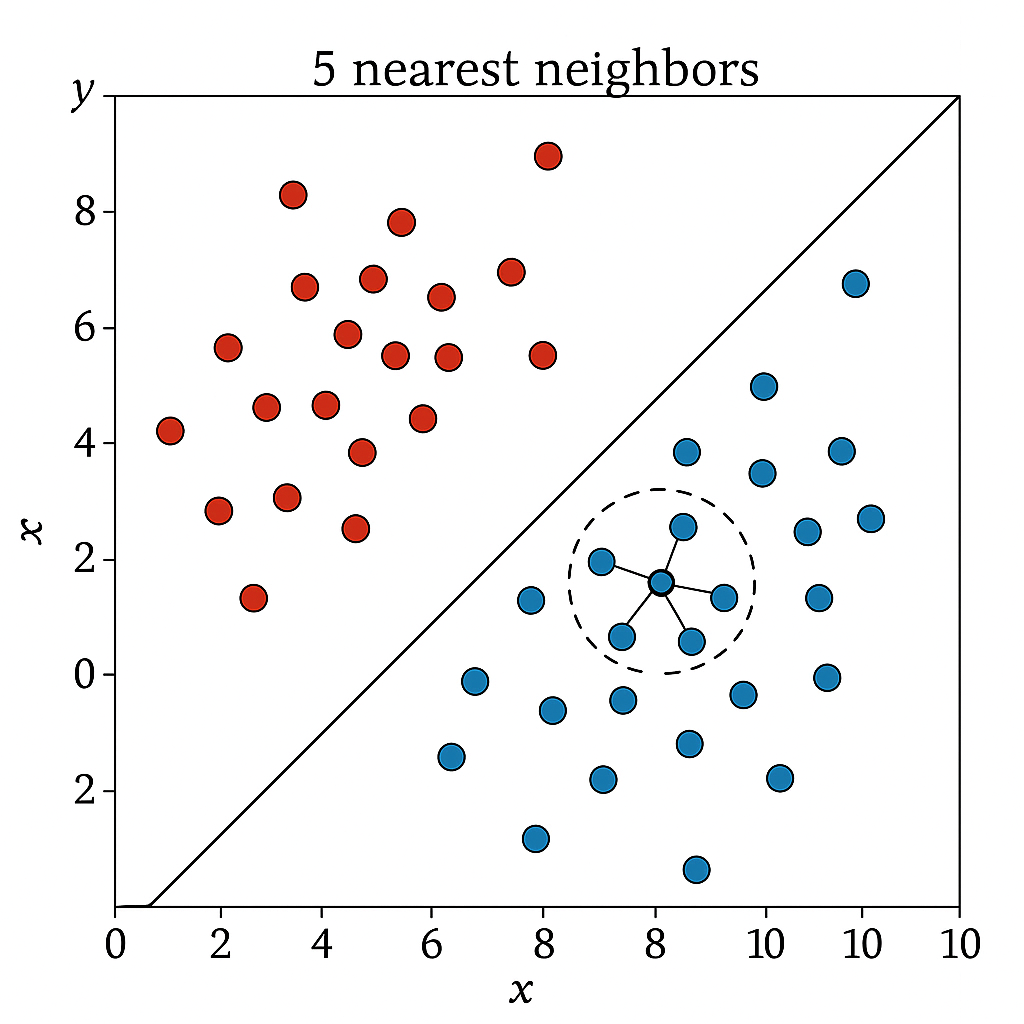
KNN classification: query point and neighbors
2. K-Means Clustering
K-Means é um método de clustering que particiona um conjunto de dados em k grupos, minimizando a variabilidade intra-grupo.
- Conceito
- Cada cluster é representado por seu centróide (média dos pontos do cluster).
- Objetivo: minimizar a soma dos quadrados das distâncias de cada ponto ao centróide mais próximo (inércia).
- Algoritmo de Lloyd
-
Inicialização: escolher k centróides (aleatório ou k-means++).
-
Repetir até convergência:
a. Atribuir cada ponto ao centróide mais próximo.
b. Recalcular centróides como média dos pontos atribuídos.