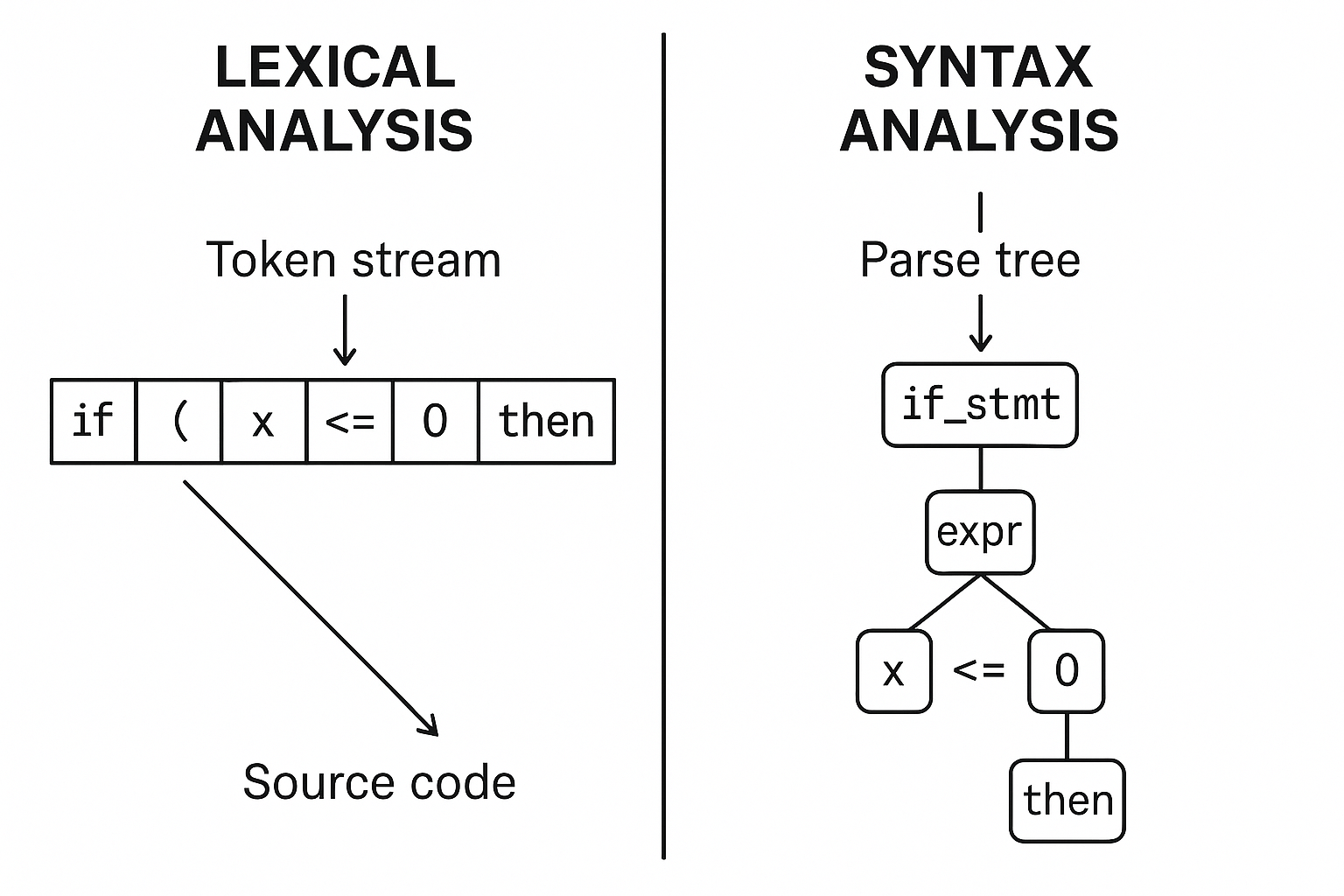
A análise léxica converte o texto-fonte em uma sequência de tokens, eliminando comentários e espaços em branco. Cada token agrupa caracteres em lexemas com significado: identificadores, números, operadores, palavras-chave.
Diagrama mostrando Análise Léxica (tokenização) vs Análise Sintática (árvore de parse)
import re
from collections import namedtuple
*# Definição de token*
Token = namedtuple('Token', ['tipo', 'valor'])
*# Expressões regulares para tokens*
token_specs = [
('NUM', r'\\d+(\\.\\d*)?'),
('ID', r'[A-Za-z_]\\w*'),
('OP', r'[+\\-*/=]'), # corrigido aqui
('LPAR', r'\\('),
('RPAR', r'\\)'),
('SKIP', r'[ \\t]+'),
('MISM', r'.'),
]
*# Compila as regex*
tok_regex = '|'.join(f'(?P<{name}>{pattern})'
for name, pattern in token_specs)
get_token = re.compile(tok_regex).match
def lexer(text):
pos = 0
tokens = []
mo = get_token(text, pos)
while mo:
tipo = mo.lastgroup
valor = mo.group(tipo)
if tipo == 'MISM':
raise SyntaxError(f'Caractere inesperado {valor!r}')
if tipo != 'SKIP':
tokens.append(Token(tipo, valor))
pos = mo.end()
mo = get_token(text, pos)
return tokens
*# Demonstração*
src = 'x = 42 + y'
print(lexer(src))
*# [Token(tipo='ID', valor='x'), Token(tipo='OP', valor='='), ...]*
A análise sintática (parsing) consome tokens e verifica se eles obedecem à gramática da linguagem, construindo uma árvore de análise (AST).
expr → term ((‘+’|‘-’) term)*
term → factor ((‘*’|‘/’) factor)*
factor → NUM | ID | ‘(’ expr ‘)’
*# Usa os tokens gerados pelo lexer anterior*
class Parser:
def __init__(self, tokens):
self.tokens = tokens
self.pos = 0
def peek(self):
return self.tokens[self.pos] if self.pos < len(self.tokens) else None
def consume(self, tipo=None):
tok = self.peek()
if tok and (tipo is None or tok.tipo == tipo):
self.pos += 1
return tok
raise SyntaxError(f'Esperava {tipo} mas obteve {tok}')
def parse(self):
node = self.expr()
if self.peek():
raise SyntaxError('Tokens extras ao final')
return node
def expr(self):
node = self.term()
while self.peek() and self.peek().valor in ('+','-'):
op = self.consume('OP')
right = self.term()
node = ('binop', op.valor, node, right)
return node
def term(self):
node = self.factor()
while self.peek() and self.peek().valor in ('*','/'):
op = self.consume('OP')
right = self.factor()
node = ('binop', op.valor, node, right)
return node
def factor(self):
tok = self.peek()
if tok.tipo == 'NUM':
return ('num', self.consume('NUM').valor)
if tok.tipo == 'ID':
return ('id', self.consume('ID').valor)
if tok.tipo == 'LPAR':
self.consume('LPAR')
node = self.expr()
self.consume('RPAR')
return node
raise SyntaxError(f'Fator inválido {tok}')
*# Demonstração*
src = '3 + 4 * (2 - x)'
tokens = lexer(src)
ast = Parser(tokens).parse()
print(ast)
*# ('binop','+',('num','3'),('binop','*',('num','4'),('binop','-',('num','2'),('id','x'))))*
Fluxo:
Conclusão: dominar esses passos é essencial para entender compiladores e ferramentas de análise de código.