Introdução ao Apache Spark
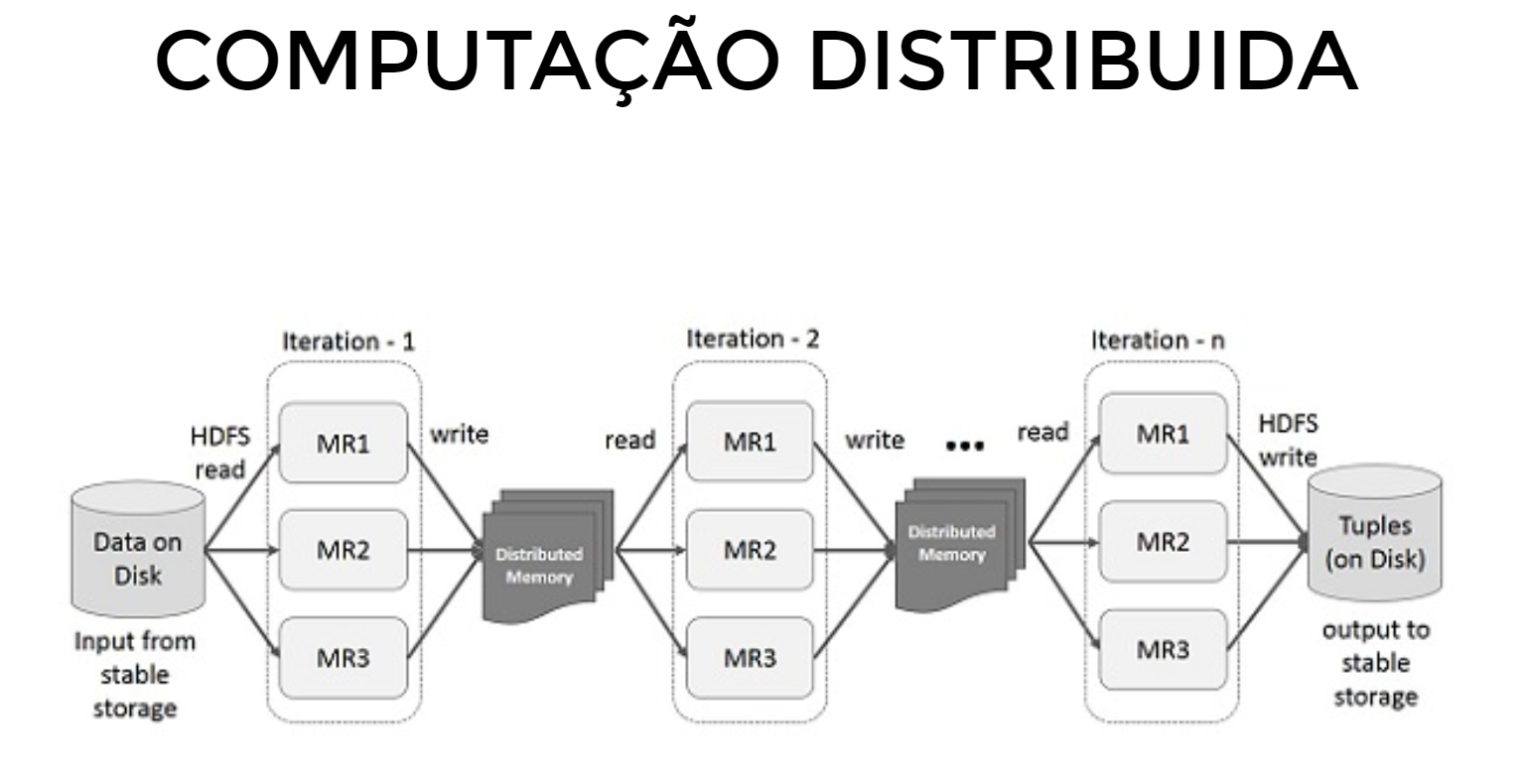
O Apache Spark é um mecanismo de processamento de dados de código aberto projetado para lidar com grandes volumes de dados de forma rápida e eficiente. Ele foi desenvolvido para superar as limitações do MapReduce, um modelo de programação utilizado no Hadoop, proporcionando maior desempenho ao realizar cálculos na memória em vez de no disco[1][3].
Componentes Principais do Spark
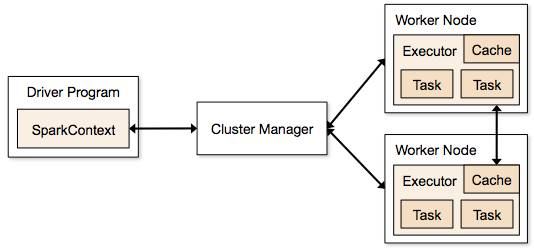
- Spark Core: É o núcleo do Spark, responsável pelo processamento de dados paralelo. Ele lida com agendamento, otimização, e abstração de dados através de RDDs (Resilient Distributed Datasets), que são coleções imutáveis e distribuídas de objetos processáveis em paralelo[1][3].
- Spark SQL: Permite consultas em dados estruturados usando DataFrames, que são uma abstração sobre RDDs. Ele suporta integração com armazenamentos de dados SQL, como Apache Hive[1].
- Spark Streaming: Oferece processamento de dados em tempo real, ingerindo dados em minilotes e permitindo análises de streaming[2].
- MLlib: Biblioteca de aprendizado de máquina que fornece algoritmos otimizados para processamento em larga escala[1].
- GraphX: Framework para processamento de gráficos, permitindo ETL, análise exploratória e computação gráfica iterativa[2].
Como Funciona
Vantagens do Apache Spark
- Processamento em Memória: O Spark realiza cálculos na memória, o que reduz a latência e aumenta a velocidade do processamento em comparação com sistemas baseados em disco[1][3].
- Suporte a Múltiplas Linguagens: Oferece APIs em Java, Scala, Python e R, tornando-o acessível para diferentes perfis de desenvolvedores[5].
- Escalabilidade: Capaz de processar grandes volumes de dados distribuídos entre muitos computadores[5].
Introdução ao PySpark
PySpark é a interface do Apache Spark para a linguagem de programação Python. Ele permite que desenvolvedores usem o poder do Spark com a simplicidade e a popularidade do Python. PySpark é amplamente utilizado para tarefas de processamento de dados, aprendizado de máquina e análise de dados em larga escala.
Funcionalidades do PySpark
- DataFrames e SQL: Assim como no Spark SQL, PySpark suporta operações em DataFrames, permitindo consultas SQL diretamente em dados estruturados.
- Machine Learning com MLlib: PySpark oferece suporte à biblioteca MLlib, permitindo a implementação de algoritmos de aprendizado de máquina em grandes conjuntos de dados.